Confident Learning, Brilliant Minds, Reliable Solution
What is machine learning?
Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.
IBM has a rich history with machine learning. One of its own, Arthur Samuel, is credited for coining the term, “machine learning” with his research (link resides outside ibm.com) around the game of checkers. Robert Nealey, the self-proclaimed checkers master, played the game on an IBM 7094 computer in 1962, and he lost to the computer. Compared to what can be done today, this feat seems trivial, but it’s considered a major milestone in the field of artificial intelligence.
Over the last couple of decades, the technological advances in storage and processing power have enabled some innovative products based on machine learning, such as Netflix’s recommendation engine and self-driving cars.
Machine learning is an important component of the growing field of data science. Through the use of statistical methods, algorithms are trained to make classifications or predictions, and to uncover key insights in data mining projects. These insights subsequently drive decision making within applications and businesses, ideally impacting key growth metrics. As big data continues to expand and grow, the market demand for data scientists will increase. They will be required to help identify the most relevant business questions and the data to answer them.
Machine learning algorithms are typically created using frameworks that accelerate solution development, such as TensorFlow and PyTorch.
Why is machine learning important?
Machine learning has played a progressively central role in human society since its beginnings in the mid-20th century, when AI pioneers like Walter Pitts, Warren McCulloch, Alan Turing and John von Neumann laid the groundwork for computation. The training of machines to learn from data and improve over time has enabled organizations to automate routine tasks that were previously done by humans -- in principle, freeing us up for more creative and strategic work.
Machine learning also performs manual tasks that are beyond our ability to execute at scale -- for example, processing the huge quantities of data generated today by digital devices. Machine learning's ability to extract patterns and insights from vast data sets has become a competitive differentiator in fields ranging from finance and retail to healthcare and scientific discovery. Many of today's leading companies, including Facebook, Google and Uber, make machine learning a central part of their operations.
As the volume of data generated by modern societies continues to proliferate, machine learning will likely become even more vital to humans and essential to machine intelligence itself. The technology not only helps us make sense of the data we create, but synergistically the abundance of data we create further strengthens ML's data-driven learning capabilities.
What will come of this continuous learning loop? Machine learning is a pathway to artificial intelligence, which in turn fuels advancements in ML that likewise improve AI and progressively blur the boundaries between machine intelligence and human intellect.

What are the different types of machine learning?
Classical machine learning is often categorized by how an algorithm learns to become more accurate in its predictions. There are four basic types of machine learning: supervised learning, unsupervised learning, semisupervised learning and reinforcement learning.
The type of algorithm data scientists choose depends on the nature of the data. Many of the algorithms and techniques aren't limited to just one of the primary ML types listed here. They're often adapted to multiple types, depending on the problem to be solved and the data set. For instance, deep learning algorithms such as convolutional neural networks and recurrent neural networks are used in supervised, unsupervised and reinforcement learning tasks, based on the specific problem and availability of data.
How does supervised machine learning work?
In supervised learning, data scientists supply algorithms with labeled training data and define the variables they want the algorithm to assess for correlations. Both the input and output of the algorithm are specified in supervised learning. Initially, most machine learning algorithms worked with supervised learning, but unsupervised approaches are becoming popular.
Supervised learning algorithms are used for several tasks, including the following:
- Binary classification. Divides data into two categories.
- Multiclass classification. Chooses between more than two types of answers.
- Ensembling. Combines the predictions of multiple ML models to produce a more accurate prediction.
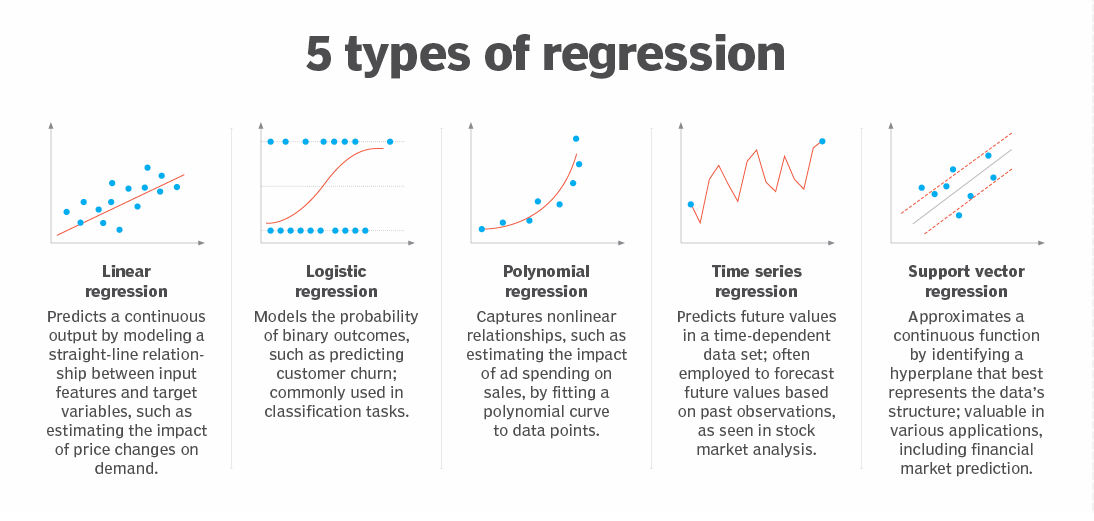
- Regression modeling. Predicts continuous values based on relationships within data.
What are the advantages and disadvantages of machine learning?
Machine learning's ability to identify trends and predict outcomes with higher accuracy than methods that rely strictly on conventional statistics -- or human intelligence -- provides a competitive advantage to businesses that deploy ML effectively. Machine learning can benefit businesses in several ways:
- Analyzing historical data to retain customers.
- Launching recommender systems to grow revenue.
- Improving planning and forecasting.
- Assessing patterns to detect fraud.
- Boosting efficiency and cutting costs.
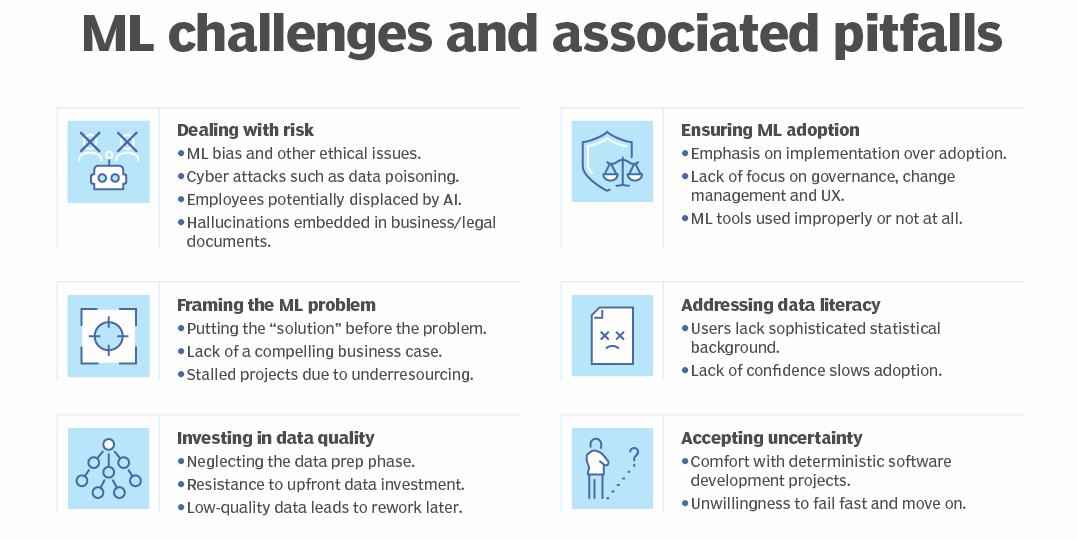
But machine learning also comes with disadvantages. First and foremost, it can be expensive. Machine learning projects are typically driven by data scientists, who command high salaries. These projects also require software infrastructure that can be expensive. And businesses can encounter many more challenges.
There's the problem of machine learning bias. Algorithms trained on data sets that exclude certain populations or contain errors can lead to inaccurate models of the world that, at best, fail and, at worst, are discriminatory. When an enterprise bases core business processes on biased models, it can suffer regulatory and reputational harm.